[GCP] GKE(Google Kubernetes Engine)에서 텐서플로우 GPU 실행하기
by Nathan Kwon
GKE(Google Kubernetes Engine) 에서 텐서플로우 GPU 실행하기
지난번에 nvidia-docker를 이용해서 도커 컨테이너 내부에서 GPU를 사용하는 예제를 포스팅했었다. 이번엔 GKE 환경에서 동작하는 컨테이너가 GPU를 사용하는 방법에 대해서 설명하겠다.
GKE에 GPU 클러스터 디플로이
GCP의 Kubernetes Engine 메뉴에 들어가서 클러스터 만들기를 선택하면 클러스터 템플릿을 선택할 수 있다. 이 중에 GPU 가속 컴퓨팅 템플릿을 선택하자.
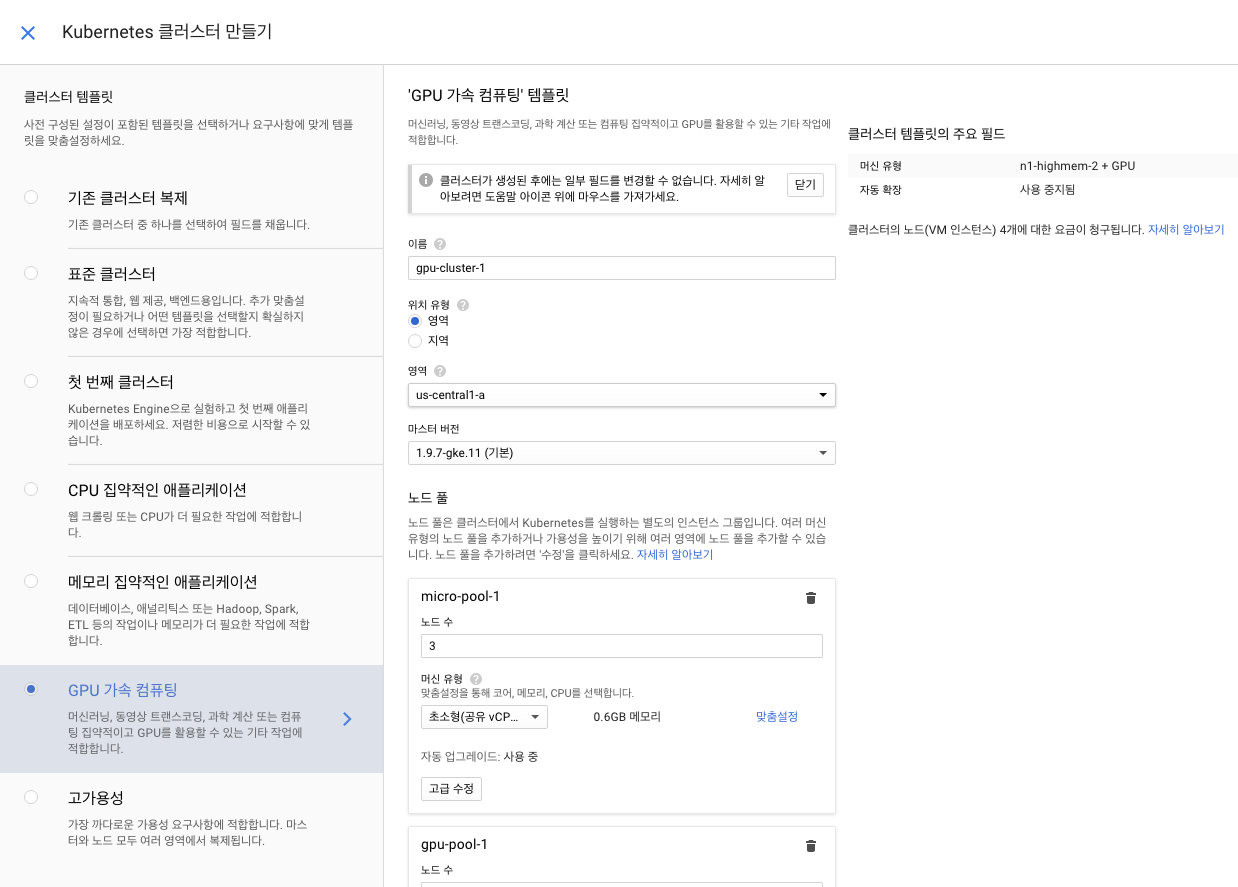
적절한 노드의 숫자를 선택해 클러스터를 만들자. 테스트에서는 micro-pool 1개 gpu-pool 1개로 클러스터를 생성했다.
NVIDIA driver 설치
gpu-pool에 있는 모든 노드에 NVIDIA 그래픽 드라이버를 설치해줘야 노드에서 실행되는 컨테이너들이 GPU를 사용할 수 있다. 다행히도 GKE에서 친절하게 미리 정의된 yaml 파일을 제공한다. 먼저 클러스터에 연결하기 위해 다음과 같이 연결 버튼을 눌러 Cloud Shell에서 실행을 클릭하면 Google Cloud Shell이 연결되고 연결 커맨드가 자동 복붙된다(진짜 편함. GKE 짱).

$ kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/stable/nvidia-driver-installer/cos/daemonset-preloaded.yaml
해당 커맨드를 실행하면 드라이버 인스톨러가 데몬셋으로 실행되어 gpu pool에 있는 노드에 드라이버가 설치된다. 다음 명령어를 이용해 설치를 확인할 수 있다.
$ kubectl -n kube-system get daemonset
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
fluentd-gcp-v2.0.17 2 2 2 2 2 beta.kubernetes.io/fluentd-ds-ready=true 1h
metadata-proxy-v0.1 0 0 0 0 0 beta.kubernetes.io/metadata-proxy-ready=true 1h
nvidia-driver-installer 1 1 1 1 1 <none> 8m
nvidia-gpu-device-plugin 1 1 1 1 1 <none> 1h
TensorFlow 컨테이너 실행
간단하게 TensorFlow에서 제공하는 도커 중 tensorflow-gpu가 설치된 도커를 사용해서 pod를 실행해보자.
apiVersion: v1
kind: Pod
metadata:
name: my-gpu-pod
spec:
containers:
- name: my-gpu-container
image: tensorflow/tensorflow:1.12.0-gpu-py3
resources:
limits:
nvidia.com/gpu: 1
pod 이 정상적으로 실행된 것을 확인한 뒤에 nvidia-smi 명령어를 통해 GPU를 인식하는지 테스트한다.
$ kubectl exec my-gpu-pod nvidia-smi
Fri Dec 7 08:12:40 2018
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 384.111 Driver Version: 384.111 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla K80 Off | 00000000:00:04.0 Off | 0 |
| N/A 48C P8 30W / 149W | 0MiB / 11439MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
다음으로 대화식으로 해당 pod에 python을 실행시킨 뒤 TensorFlow 세션을 만들어서 GPU를 인식하는지 테스트 해보자.
$ kubectl exec -it my-gpu-pod python
Python 3.5.2 (default, Nov 23 2017, 16:37:01)
[GCC 5.4.0 20160609] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import tensorflow
>>> tensorflow.Session()
2018-12-07 08:15:58.100620: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
2018-12-07 08:15:58.205242: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:964] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2018-12-07 08:15:58.205804: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1432] Found device 0 with properties:
name: Tesla K80 major: 3 minor: 7 memoryClockRate(GHz): 0.8235
pciBusID: 0000:00:04.0
totalMemory: 11.17GiB freeMemory: 11.10GiB
2018-12-07 08:15:58.205947: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1511] Adding visible gpu devices: 0
2018-12-07 08:15:58.548558: I tensorflow/core/common_runtime/gpu/gpu_device.cc:982] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-12-07 08:15:58.548636: I tensorflow/core/common_runtime/gpu/gpu_device.cc:988] 0
2018-12-07 08:15:58.548653: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1001] 0: N
2018-12-07 08:15:58.549096: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 10757 MB memory) -> physical GPU (device: 0, name: Tesla K80, pci bus id: 0000:00:
04.0, compute capability: 3.7)
<tensorflow.python.client.session.Session object at 0x7f89abf36ef0>
로그를 확인하면 정상적으로 GPU를 인식한 것을 확인할 수 있다.
결론
생각보다 GKE 환경에서 GPU를 사용하는게 어렵진 않다. GPU 드라이버 설치 부분이 미리 정의되어 있다는 것이 가장 큰 이유일 것이다. TensorFlow에서 GPU를 사용하고자 할 때는 항상 NVIDIA 드라이버 버전과 CUDA, cuDNN, 그리고 TensorFlow의 버전이 호환되는지 항상 먼저 확인하자.
Subscribe via RSS